Het periodiek systeem van AI: zo beoordeel je of een AI-systeem echt werkt
- JumpScale
- Ai, Compliance
- 14 februari 2026
Elke AI-pitch klinkt indrukwekkend. Maar hoe beoordeel je of een AI-systeem echt doet wat het belooft? Het AI Periodiek Systeem ontleedt AI in zeventien bouwstenen. Wij gebruiken het als beoordelingskader bij AI-audits. Dit artikel laat zien hoe het werkt.
Inhoudsopgave
Je krijgt een demo. Indrukwekkend. De AI beantwoordt vragen over je eigen documenten. De verkoper noemt het “RAG-powered.” Je knikt. Maar weet je wat er onder de motorkap zit? En belangrijker: weet je wat er ontbreekt?
Dat is het probleem met AI in 2026. Alles klinkt goed. De demo’s zijn overtuigend. Maar 95% van AI-pilots levert geen meetbare impact (MIT, 2025). 42% van bedrijven heeft AI-initiatieven alweer gestaakt. Niet omdat AI niet werkt. Maar omdat niemand beoordeelt of het juiste systeem voor het juiste probleem wordt ingezet.
Het AI Periodiek Systeem in het kort:
- AI-systemen bestaan uit zeventien herkenbare bouwstenen
- Van simpele prompts tot multi-agent systemen: elke rij is complexer
- Het model werkt als beoordelingskader: wat zit erin, wat ontbreekt, klopt de complexiteit?
- Vier rode vlaggen die je direct kunt checken bij elke AI-demo
Zeventien bouwstenen van AI
Martin Keen, Master Inventor bij IBM met meer dan 400 patenten, ontwikkelde het AI Periodiek Systeem. Het idee is verrassend simpel: net zoals het echte periodiek systeem alle chemische elementen ordent, ordent dit model alle bouwstenen van AI. Elk AI-systeem dat je tegenkomt, van ChatGPT tot de “AI-agent” die je vendor verkoopt, is opgebouwd uit een combinatie van deze elementen.
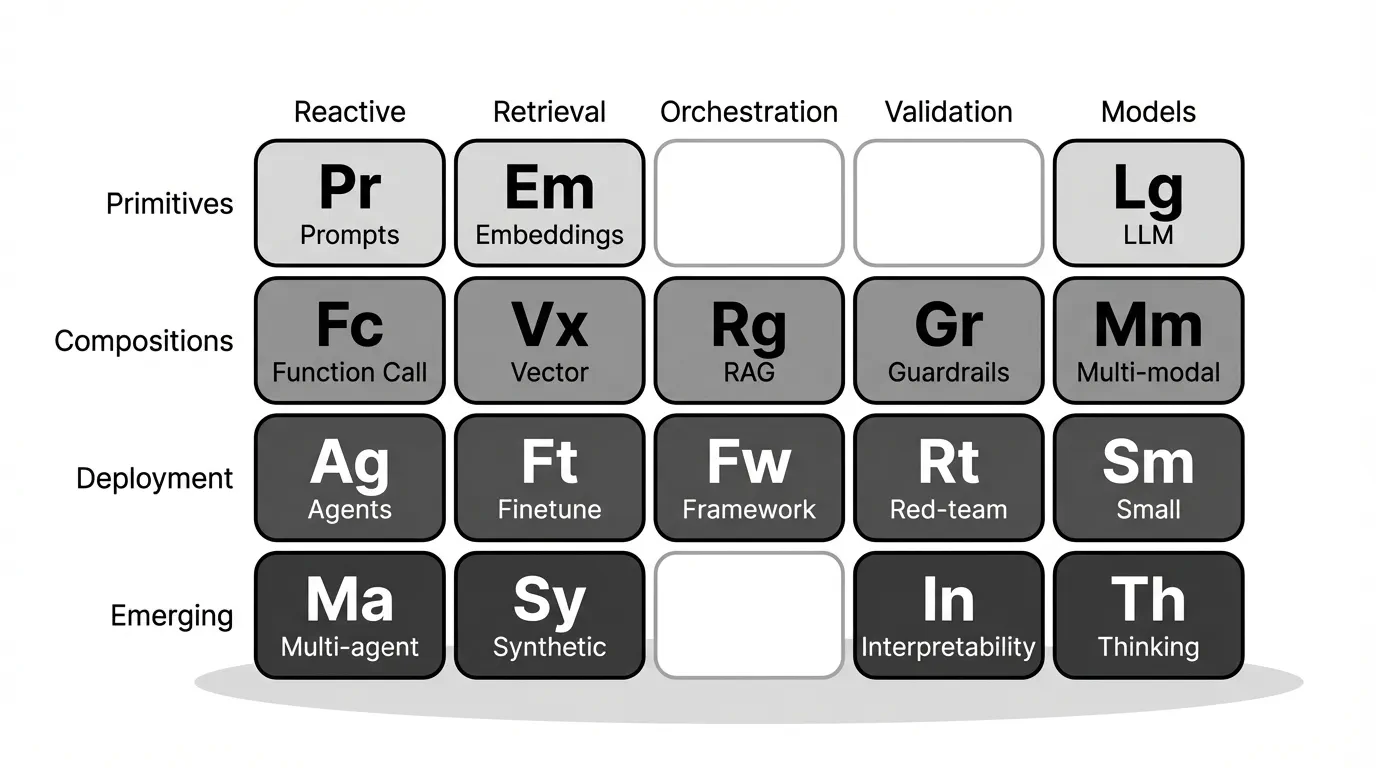
Vier rijen, vier complexiteitsniveaus. Hoe hoger de rij, hoe geavanceerder het systeem.
| Rij | Niveau | Elementen | In het kort |
|---|---|---|---|
| 1 | Primitives | Prompts, Embeddings, LLMs, Tokens, Attention | Je typt iets, je krijgt iets terug. Dit is ChatGPT. |
| 2 | Compositions | Function Calling, Vector Databases, RAG, Guardrails, Multi-modal | De AI gebruikt jouw data. Hier wordt het interessant voor bedrijven. |
| 3 | Deployment | Agents, Fine Tuning, Frameworks, Red Teaming, Small Models | De AI handelt zelfstandig. Productie. |
| 4 | Emerging | Multi-Agent, Synthetic Data, Interpretability, Thinking Models | Frontier-technologie. Experimenteel. |
Rij 1 is waar iedereen begint. Je stelt een vraag, je krijgt een antwoord. Geen verbinding met je bedrijfsdata, geen actie in andere systemen. Gewoon een slim chatvenster.
Rij 2 is waar het voor bedrijven interessant wordt. RAG (Retrieval Augmented Generation) betekent dat de AI je documenten doorzoekt voordat hij antwoord geeft. Guardrails voorkomen dat de AI dingen zegt of doet die niet mogen. Function Calling laat de AI acties uitvoeren in andere systemen. Dit is het niveau waarop de meeste zakelijke AI-toepassingen draaien.
Rij 3 gaat over productie en autonomie. Agents denken, handelen, observeren en herhalen, zelfstandig. Fine Tuning past een model aan op jouw specifieke domein. Red Teaming test het systeem door het actief te proberen te breken. We schreven eerder over het verschil tussen vibe coding en agentic coding, agents zijn precies dat snijpunt.
Rij 4 is frontier. Multi-agent systemen waarin meerdere AI’s samenwerken. Thinking Models die hun eigen redenering kunnen uitleggen. Interpretability die inzichtelijk maakt waarom een AI een bepaalde beslissing nam. De meeste bedrijven hebben dit niet nodig. Maar het wordt wel verkocht alsof ze het nodig hebben.
74,4% van het Nederlandse MKB gebruikt inmiddels AI. Maar slechts 8% doet dat organisatiebreed. De rest experimenteert, vaak zonder te weten op welk niveau ze zitten.
Vier manieren om een AI-systeem te beoordelen
Het periodiek systeem is geen decoratie. Het is een gereedschap. Zo gebruik je het.
1. Architecture mapping: wat zit erin?
Vraag de aanbieder welke elementen in hun systeem zitten. Niet in marketingtaal, maar concreet. Gebruikt het RAG? Dan moet er een vector database zijn. Zit er een LLM in? Welk model, welke versie? Worden er guardrails toegepast?
Een concreet antwoord klinkt zo: “We gebruiken GPT-4o als LLM, Pinecone als vector database, en we hebben input- en output-guardrails voor hallucination detection.” Dat is rij 2, helder omschreven.
Een vaag antwoord klinkt zo: “We gebruiken de nieuwste AI-technologie.” Dat is een rode vlag.
2. Gap analysis: wat ontbreekt?
Dit is minstens zo belangrijk als wat erin zit. Een RAG-systeem zonder guardrails betekent dat de AI alles kan zeggen, ook dingen die fout, schadelijk of juridisch riskant zijn. Geen red teaming? Dan weet je niet hoe het systeem reageert op misbruik.
We beschreven eerder hoe 45% van AI-code kwetsbaar is door ontbrekende checks. Hetzelfde geldt voor AI-systemen: wat er niet in zit, bepaalt het risico.
3. Complexiteitscheck: past het bij het probleem?
Een veelgemaakte fout: een rij 4 systeem verkopen voor een rij 2 probleem. Bedrijven betalen voor multi-agent architecturen terwijl een simpele RAG-toepassing volstaat.
De vraag is niet “hoe geavanceerd is het?” maar “past de complexiteit bij wat ik nodig heb?” Meer complexiteit betekent hogere kosten, meer onderhoud en meer dat fout kan gaan.
Concreet: een MKB-bedrijf dat een FAQ-bot wil voor klantservice heeft genoeg aan rij 2. Een LLM, RAG op de kennisbank, en guardrails die voorkomen dat de bot onzin verkoopt. Daar heb je geen multi-agent systeem of fine-tuning voor nodig. Betaal er ook niet voor.
4. Reactiecheck: kloppen de combinaties?
Sommige combinaties zijn logisch verplicht. RAG zonder vector database is geen echte RAG, dan zoekt de AI niet in je documenten, maar doet hij alsof. Een agent zonder guardrails is een autonome AI zonder rem. Function Calling zonder authenticatie geeft de AI toegang tot systemen zonder controle.
Als een aanbieder beweert rij 3 te leveren maar de essentialia van rij 2 ontbreken, klopt er iets niet.
Drie AI-claims die je nu kunt doorprikken
Geen abstracte theorie. Dit zijn drie situaties die je morgen kunt tegenkomen. Bij elke claim laten we zien wat het in periodiek-systeem-termen betekent, en welke vraag je stelt om de claim te toetsen.
“Onze AI leert van je bedrijfsdata”
Klinkt goed. Maar dit kan drie heel verschillende dingen betekenen:
- RAG (rij 2): De AI zoekt in je documenten en gebruikt die als context. Je data blijft waar die staat.
- Fine-tuning (rij 3): Het AI-model wordt daadwerkelijk aangepast op jouw data. Duurder, complexer, en je data gaat naar het model.
- System prompt met context: De simpelste variant. Je data wordt als tekst meegegeven bij elke vraag. Geen duurzame “leer”-capaciteit.
Drie heel verschillende dingen qua privacy, kosten en effectiviteit. Bij RAG blijft je data in eigen beheer. Bij fine-tuning wordt je data onderdeel van het model, en kun je die niet meer terughalen. Bij een system prompt verdwijnt de context na elk gesprek.
De vraag die je stelt: “Blijft mijn data bij jullie, of gaat het naar het AI-model?”
“Wij hebben een AI-agent die dit automatisch afhandelt”
Het woord “agent” wordt te pas en te onpas gebruikt. Een echte agent (rij 3) denkt, handelt, observeert het resultaat en herhaalt. Hij kan zelfstandig beslissingen nemen.
Veel “agents” zijn chatbots met if-then regels. Niets mis mee, maar het is rij 1, niet rij 3. Het verschil zit in autonomie: kan het systeem zelfstandig een taak oppakken, tussentijds bijsturen en het resultaat evalueren? Of volgt het een vast script?
De Carnegie Mellon AgentCompany benchmark toont hoe lastig echte agents zijn: de beste AI-agent voltooit slechts 24% van complexe taken zelfstandig. Agents zijn krachtig, maar ze zijn ook onvoorspelbaar als de kaders ontbreken. Afzonderlijk onderzoek laat zien dat 39% van bedrijven rapporteert dat AI-agents onbedoelde systemen benaderden.
De vraag die je stelt: “Wat kan de agent zelfstandig beslissen, en waar zit de rem?”
“Ons systeem is volledig veilig”
Dit is de claim waar je het meest alert op moet zijn. Check drie dingen:
- Guardrails (rij 2): Zijn er regels die bepalen wat de AI wel en niet mag doen?
- Red Teaming (rij 3): Is het systeem getest door iemand die het probeerde te breken?
- Interpretability (rij 4): Kun je achteraf zien waarom de AI een bepaald antwoord gaf?
Als geen van drieen aanwezig is, is “volledig veilig” een marketingclaim. Geen technische waarheid. Geen enkel AI-bedrijf scoort hoger dan C+ op de AI Safety Index (Future of Life Institute, 2025).
De voorbeelden zijn pijnlijk concreet. Chevrolet’s chatbot stemde in met de verkoop van een auto van $70.000 voor $1, geen guardrails. Air Canada’s chatbot gaf fout reisadvies en het bedrijf werd juridisch aansprakelijk gesteld. 12% van AI skills is malicious, ontworpen om data te stelen.
De vraag die je stelt: “Wat hebben jullie gedaan om het systeem te breken voordat het live ging?”
FTC en SEC handhaven inmiddels actief tegen AI-washing, bedrijven die meer beloven dan hun technologie waarmaakt. In Nederland is de ACM de toezichthouder. De richting is duidelijk: wie claimt dat iets “veilig” is, moet dat kunnen aantonen.
Hoe wij het periodiek systeem gebruiken
We gebruiken het periodiek systeem op twee manieren. En de tweede is misschien de waardevollere.
Beoordelen: achteraf toetsen. Wanneer we een bestaand AI-systeem auditen, mappen we het op het periodiek systeem. Welke elementen zijn aanwezig? Welke ontbreken? Past de complexiteit bij het probleem? Wat we dan vaak tegenkomen: systemen die op rij 3-4 worden verkocht maar eigenlijk rij 1-2 zijn. Een “AI-agent” die bij nader inzien een chatbot is met drie if-then regels. Een “RAG-systeem” dat geen vector database heeft maar gewoon een system prompt met wat tekst erin.
Ontwerpen: vooraf specificeren. Het periodiek systeem is minstens zo waardevol aan de voorkant. Wanneer we met een klant aan tafel zitten om een AI-toepassing te ontwerpen, leggen we het model erbij. Welke elementen heb je nodig voor dit probleem? Waar hoef je niet aan te beginnen? Moet je op rij 2 zitten of is rij 1 genoeg? Dat voorkomt over-engineering voordat er ook maar één regel code is geschreven. En het geeft de klant dezelfde taal om mee te denken. Geen mysterieuze afkortingen, maar een overzicht dat je samen kunt invullen.
We zien ook patronen die steeds terugkomen. Systemen op rij 2 die essentialia missen: RAG zonder guardrails, function calling zonder authenticatie. Bij 97% van organisaties met AI-breaches ontbraken basale toegangscontroles (IBM, 2025). Als je het periodiek systeem vooraf invult, zie je die gaten voordat ze problemen worden.
Het model maakt gesprekken concreet. Geen meningen, maar een checklist. AI-native worden begint met begrijpen wat je bouwt, en wat je bewust weglaat.
Vijf vragen voor je volgende AI-demo
Knip deze uit. Print ze. Neem ze mee naar je volgende gesprek met een AI-aanbieder. Je hoeft geen technische achtergrond te hebben om deze vragen te stellen. De antwoorden vertellen je genoeg.
“Welke elementen uit het AI Periodiek Systeem zitten in jullie product?” Een goede partij kan dit concreet beantwoorden. “We gebruiken een LLM met RAG, vector database en guardrails.” Niet: “We gebruiken de nieuwste AI-technologie.”
“Wat ontbreekt er bewust, en waarom?” Elk systeem maakt keuzes. Fine-tuning is niet altijd nodig. Multi-agent ook niet. Maar de aanbieder moet kunnen uitleggen waarom ze iets niet doen.
“Wat gebeurt er als de AI het fout heeft?” Dit test of er guardrails zijn. Kan de AI onbeperkt antwoorden geven? Of zijn er grenzen ingebouwd? Wat gebeurt er bij een fout antwoord?
“Is het systeem getest door iemand die het probeerde te breken?” Red teaming. Als het antwoord nee is, weet niemand hoe het systeem reageert op misbruik. En dat is precies het soort nalatigheid waar toezichthouders nu op letten.
“Waar gaat mijn data naartoe?” Privacy check. Blijft je data lokaal? Gaat het naar een cloud-provider? Wordt het gebruikt om het model te trainen? De EU AI Act maakt risicobeheersing voor AI verplicht vanaf augustus 2026. Weet nu al waar je staat.
Hulp nodig?
Wil je weten wat er echt in een AI-systeem zit? We kijken samen. Geen verkooppraatje, een eerlijk gesprek.
Bronnen: IBM Technology, The AI Periodic Table (Martin Keen), Fortune, 95% of AI Pilots Fail (MIT, aug 2025), Carnegie Mellon AgentCompany Benchmark, IBM Cost of a Data Breach Report 2025, S&P Global, 42% of AI Initiatives Discontinued, Future of Life Institute, AI Safety Index, EU AI Act